What are Orchestration services
Orchestration is the planning or coordination of the elements of a situation to produce the desired effect. In the world of data and AI, our day-to-day work involves munging datasets of millions of rows, building insights out of making it a stable recurring process. To do this, we need to orchestrate these jobs.
To do orchestration there are a lot of external tools in the market: open-source tools like e.g., Apache Oozie & Apache Airflow and some cloud-native tools such as Azure Data Factory, AWS Step Functions etc. A recent addition to the list is Databricks workflow; a fully-managed orchestration service for Lakehouse.
Why Databricks Workflows
To clarify Databricks Workflow we need to clarify first how the lifecycle of any orchestration tool works:
- In most tools, orchestrations work & are written as DAG (or Direct Acyclic Graphs) which consist of tasks and the dependencies between them. A DAG dictates the order of tasks in which they must run, which tasks depends on what others and how often this DAG should be run.
- A DAG does not care about what is happening inside the tasks, it merely concerns with how to execute them; these could be Python tasks, SQL tasks, Command Line tasks or anything else. Below a generic representation of how every DAG behaves.
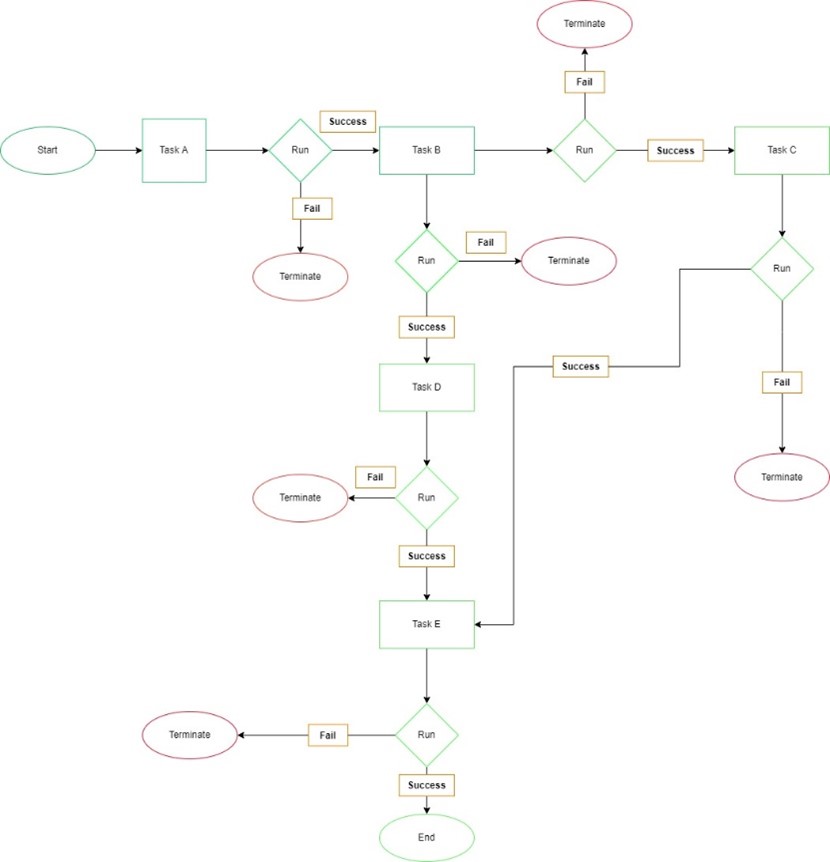
Databricks Workflow offers a fully managed orchestration platform. This means:
- It offers an orchestration platform embedded within the broader Databricks platform.
- It’s available through three different interfaces incl. the Workflows UI, expressive APIs and Databricks CLI.
- It allows to easily create, run, monitor and repair data pipeline without managing any infrastructure.
- It enables autonomy in design and ETL processes.
- It has native monitoring capabilities to quickly identify and diagnose issues (table and matrix view of workflow runs)
- It saves the overhead of learning every nook and cranny of (yet another) tool set.
How to set up a Workflow

Step 1: Click on workflows and then create a job.
Step 2: Specify the name of the job and then select the notebook you want to schedule from the path pane.
Step 3: Select the cluster if you wish to run it on the existing all-pupose cluster otherwise leaving the default setting it will create a job cluster to run this job.
Step 4: Click on “Create Task” and it will appear as a task on the page.
Step 5: To add the next task click on 
Step 6: Repeat the steps from 1 to 4, you will notice a new text box “dependency” appearing with your previous job present in it.
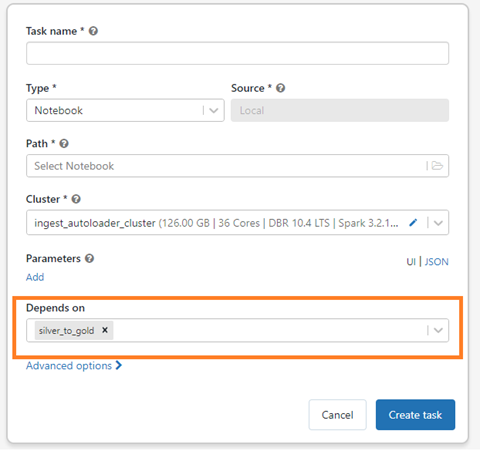
Step 7: And your DAG is ready, you can click on “Run Now”.
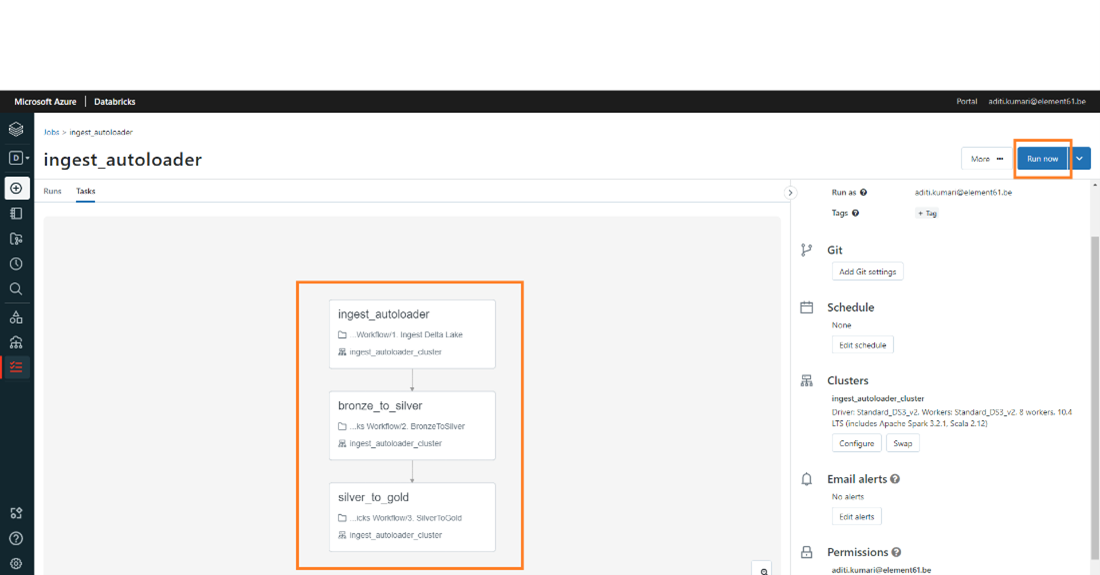
Some of the cool features of running a Workflow:
- Git settings: You can run the notebook tasks from git repo of a specific branch , tag or a commit.
- Schedule: You can choose either a manual schedule or specify the cron entry you want to run the job as.
- Cluster: You have options to specify the cluster
- When you are creating the workflow
- Once your workflow is created , you can reconfigure or swap the existing cluster.Email alerts : You can configure alerting for start, failure, success and include skipped runs.
If you are looking for the right orchestration tool or keen to have an extensive demo on Databricks Workflow, do reach out!