Microsoft Fabric is the new Microsoft branded analytics platform that integrates data warehousing, data integration and orchestration, data engineering, data science, real-time analytics, and business intelligence into a single product. This new one-stop shop for analytics brings a set of innovative features and capabilities by providing a transformative tool for data professionals and business users. With Microsoft Fabric, you can leverage the power of data and AI to transform your organization and create new opportunities.
For more Microsoft Fabric topics 👉 Microsoft Fabric | element61
Why should you be eager to explore this insightful content
Unleash the boundless potential of Microsoft Fabric, which can seamlessly integrate with your Databricks data lakehouse. In this insight you will discover the benefits of using Microsoft Fabric on top of your enterprise data, specifically when exploring the Direct Lake feature and its relevance to your modern data platform. And finally, you will uncover the easiness of integrating both worlds.
The information is intended for individuals or for companies who have invested in a Databricks-enabled data lakehouse and seek to utilize Microsoft Fabric as a reporting tool. In the image below you see a diagram of your modern data platform using Databricks as a transformation engine where only the semantic layer will be served by Microsoft Fabric instead of Power BI.
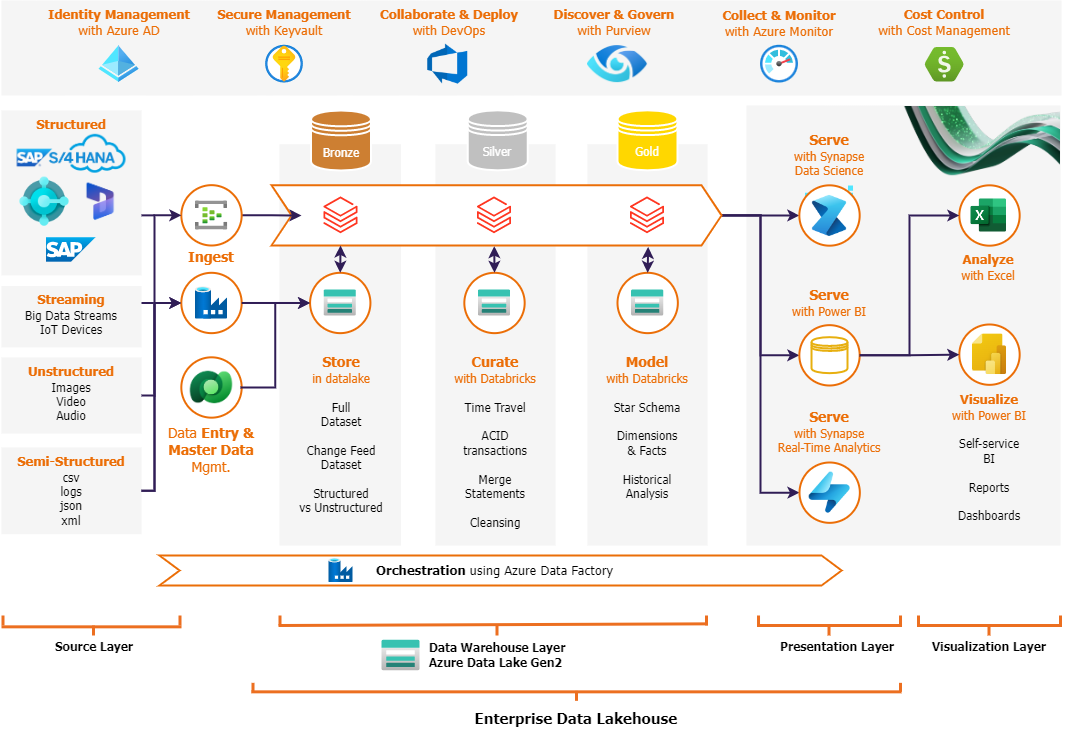
By harnessing the power of Direct Lake, you can enhance compatibility between Microsoft Fabric and your Databricks lakehouse (explained in the next chapter).
What is Power BI Direct Lake mode and V-ORDER
I can refer to a quote on the Microsoft documentation describing the new nifty feature of the Power BI Direct Lake novelty.
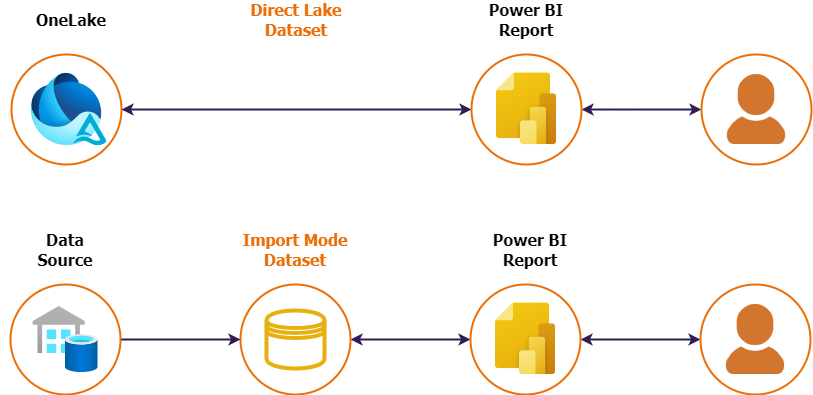
Direct Lake mode introduces an innovative dataset capability for analysing large data volumes in Power BI. It enables loading parquet-formatted files directly from a data lake without the need for querying a Lakehouse endpoint or importing data into a Power BI dataset. With Direct Lake, data is loaded efficiently into the Power BI engine for swift analysis.
In other words, Power BI Direct Lake mode is kind of a direct query connection to your data lake, with the advantage that Power BI can swiftly load data without the overhead of translating a Power BI action into queries that are executed against the data lakehouse. This performance is influenced by how your data is structured in the data lake. The Delta file format plays a crucial role in enhancing performance, but to achieve blazing-fast visuals in Power BI, the V-ORDER algorithm comes into play.
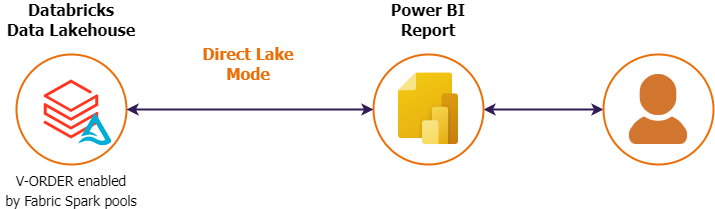
V-ORDER compresses and reorders data in your delta files in your data lakehouse, optimizing it for a seamless visualization experience in Power BI and other Microsoft Fabric workloads (like SQL endpoints). It provides an in-memory-like experience. The V-Order optimization will become standard for every newly created table in the Microsoft Fabric data lakehouse.
At this moment though, the algorithm is not available as an optimization technique in the Databricks workspace. But V-Order is 100 percent compliant with the open Delta format, so V-ORDER is fully compatible with Databricks as a processing engine, enabling optimization of delta files on data lakes using Microsoft Fabric and a Spark pool. This results in the fact that you can leverage Direct Lake mode on top of your gold layer, created by Databricks engines, and optimized by the Microsoft Fabric spark compute engine. A symbiosis of two worlds 👌
If you want to have some insights into the performance comparison between Direct Lake and the other import modes. You can always read a great article benchmarking these against each other called Comparing Direct Lake and Import Mode in Power BI.
How to activate V-ORDER on a Databricks-powered Data Lakehouse
The steps to take are rather simple. First, you need to shortcut your Databricks-powered data lakehouse to Microsoft OneLake. Be sure that the table is a delta table, otherwise it won't work. When shortcutting Databricks Data Lakehouse, the table will become visible in your Microsoft Fabric workspace. Then, we optimize the table using a Spark notebook in Microsoft Fabric:
%%sql
OPTIMIZE <table|fileOrFolderPath> VORDER;
The <table|fileOrFolderPath> placeholder should be replaced by the table name.
You can verify if your delta table is V-ORDER optimized, by exploring the data lake files using the Azure Storage Explorer. In the last section of the delta log you will find a key describing that your delta table is V-ORDER enabled:
{
"commitInfo": {
"timestamp": 1687761859733,
"operation": "OPTIMIZE",
"operationParameters": {
"predicate": "[]",
"auto": false,
"zOrderBy": "[]"
},
"readVersion": 75,
"isolationLevel": "SnapshotIsolation",
"isBlindAppend": false,
"operationMetrics": {
"numRemovedFiles": "12",
"numRemovedBytes": "2167998",
"p25FileSize": "1505348",
"minFileSize": "1505348",
"numAddedFiles": "1",
"maxFileSize": "1505348",
"p75FileSize": "1505348",
"p50FileSize": "1505348",
"numAddedBytes": "1505348"
},
"tags": {
"VORDER": "true"
},
"engineInfo": "Apache-Spark/3.3.1.5.2-92314920 Delta-Lake/2.2.0.4",
"txnId": "b945226b-16fd-4321-8782-b04fa329be3f"
}
You can find more information of the structure of delta tables in this insight at Databricks Delta.
What is the conclusion
You can use Microsoft Fabric workloads to enable the ultimate Direct Lake mode experience on top of a data lakehouse powered by Databricks. Using the V-ORDER optimization technique, Direct Lake mode is supercharged, and you can use the performance to its fullest extent.
A true symbiosis between two top-notch modern data platform engines is achieved! 🚀



