What is “Delta Lake”
Delta Lake is an open-format storage layer that delivers reliability, security, and performance on data lakes for streaming and batch operations.
Off-the-shelf key features of Delta lake are
- ACID transactions (Optimistic concurrency Control)
- UPDATE/MERGE/DELETE operations
- Schema enforcement and evolution
- Time-Travel
- Unified Batch and streaming operations
- Change Data Capture
With Delta Lake, you can build Lakehouse architecture with the option to choose from a variety of compute engines including Spark, Flink, Hive, Azure Synapse, and many more to join the lot in the future.
Where is Delta Lake used
Although Delta Lake is curated by the founders of spark (Databricks), it goes a lot further than Spark & breaks boundaries. You can use Delta Lake across cloud platforms (Azure, AWS, GCP) and across compute environments such as e.g. Azure Data Factory, Python, Synapse Analytics, Flink, etc.
Delta Lake shines best on an analytical Data Lake but has ACID functionalities and can thus perfectly be used in real-time, in data products, APIs, etc. What Delta Lake does well is taking the typical challenges of an analytical system such as incremental load, change data capture & data sharing, and offering them as a key capability: Delta Lake has in-built capabilities & configurations to support the above instead of spending efforts on building these capabilities all by yourself.
Delta Lake “Under the hood”:
The benefits of using Delta Lake are amazing but curious minds always wonder, what’s Under the hood.
Simply put, Delta Lake is a self-contained folder hierarchy containing transaction log built on top of parquet storage format. The building blocks of Delta lake are
- The Transaction log: a _delta_log folder containing JSON and Parquet files. These files contain schema to refer, file references, metadata, and metrics.
Transaction log keeps the data up-to-date by logging one file/version per transaction and hence enabling time travel, streaming, and optimistic concurrency control.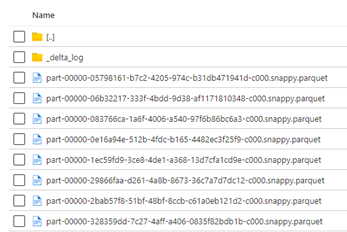
- The storage layer: When Writing data in delta format, you can specify the location. In these storage layers – like an Azure Data lake Gen2 environment - Delta lake stores the data in parquet format at the prespecified location.
- The Delta table: The Delta Table is how the data is represented for the consuming users. Through the Delta Table API (Python, Spark & many more), users & developers can read/write data easily without having the abstraction of parquets or log-folders. The Delta API supports all types of operations incl. UPSERT, DELETE , ACID transactions, time travel & many more.
- The Delta engine is the actual engine doing the work. Most often in our scenario, the Delta engine is a Spark Cluster with the latest Databricks Runtime package and – as such – latest Delta Lake capabilities. Within Databricks we are sure that the Delta Engine
- optimizes queries making through use of AQE (Adaptive query execution), Dynamic runtime filters and Cost-based Optimization technique of Spark 3.0.
- has a caching layer that auto-selects which input data to be cached, transcodes it and leverages the scan performance resulting in increased storage speeds.
- has native vectorized execution engine “Photon”, an engine within the engine, written in C++ and utilizes instruction-level parallelism in CPUs to harness maximum efficiency from modern hardware.
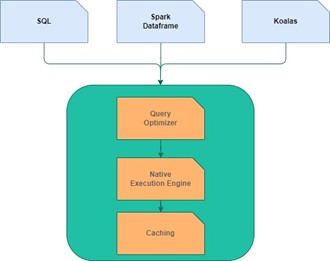
All components together, the anatomy of a query running on Delta Lake runs like this:
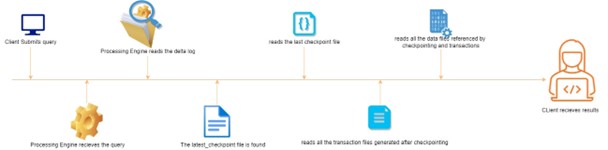
When a query is fired from client interface, the processing engine receives the query, reads the _delta_log and finds out the _last_checkpoint file. If the _last_checkpoint file exists, it refers to the last checkpoint file & the processing engine reads the last checkpoint file and all other transactions coming after checkpointing. Merging all these changes together the results are then returned to client interface.
Want to know more
By understanding the above internals of Delta Lake, we think it will be easier for data engineers to organize their data, trust the functionalities & leverage Delta Lake with its full potential. To know more on Delta Lake and Lakehouse implementations, get in touch with us!




