What is Azure Language Cognitive Service
 Azure Language Cognitive Service is a cloud-based service that provides natural language processing (NLP) features for understanding and analyzing text. The Language Cognitive Service unifies the previously available Cognitive Services: Text Analytics, QnA Maker and LUIS (Language Understanding).
Azure Language Cognitive Service is a cloud-based service that provides natural language processing (NLP) features for understanding and analyzing text. The Language Cognitive Service unifies the previously available Cognitive Services: Text Analytics, QnA Maker and LUIS (Language Understanding).
With this service, users can build intelligent applications using the web-based Language Studio, REST APIs, and client libraries based on preconfigured AI models that can be fine-tuned to fit your scenario.
The Language Cognitive Service entails six services each with specific features. The six core services can be summarized as very logical building blocks:
-
Extract Information: This building block allows you to identify and extract entities, key phrases, and other information from unstructured text. You can use preconfigured models or create your own custom models to handle domain-specific scenarios.
- Summarize Content: This building block allows you to generate concise summaries of documents and conversation transcripts. You can use this feature to highlight the most important or relevant information within the original content.
- Classify Text: This building block allows you to categorize text into predefined or custom classes. You can use this feature to organize and filter text data based on your business or application needs.
- Answer Questions: This building block allows you to provide answers to user questions based on a given context or document. You can use this feature to create interactive and informative experiences for your users.
- Understand Conversations: This building block allows you to analyze and understand natural language conversations. You can use this feature to create conversational agents, chatbots, or voice assistants that can respond to user intents and queries.
- Translate Text: This building block allows you to translate text from one language to another in real-time. You can use this feature to enable cross-lingual communication and collaboration for your users.
Within those building blocks, the following features are – according to us – the most relevant to understand:
The most available features are:
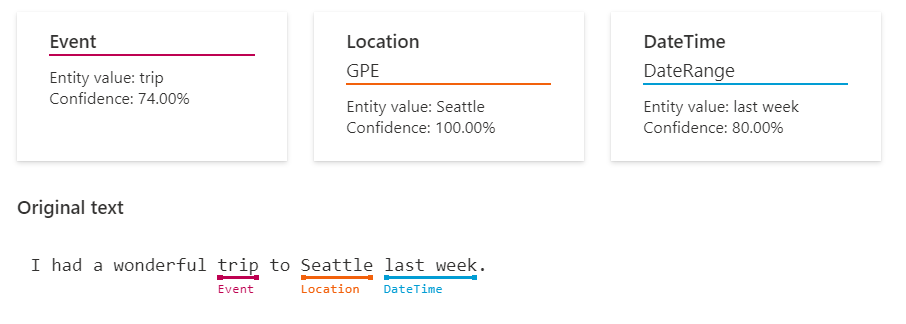
- Named Entity Recognition (NER): This feature identifies and categorizes entities (words or phrases) in unstructured text across several predefined category groups, such as people, events, places, dates, and more.
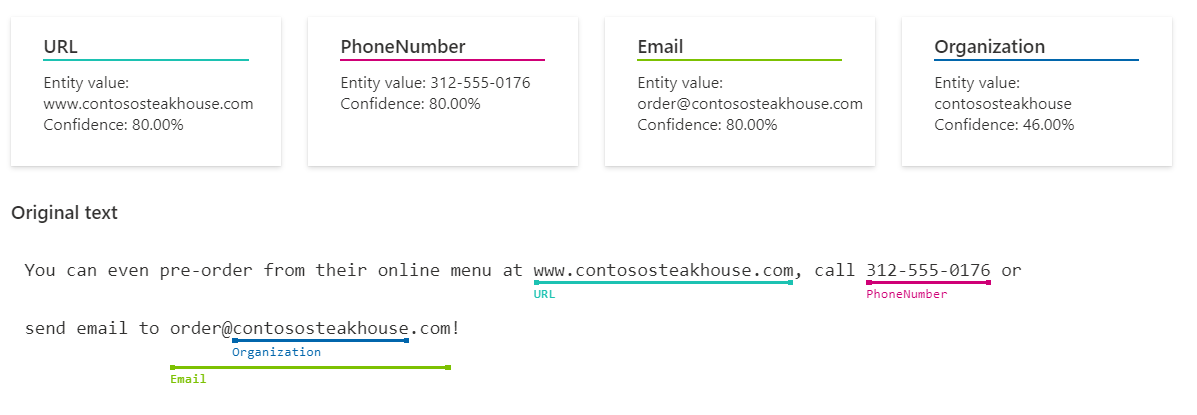
- Personally Identifying (PII) and Health (PHI) Information Detection: This feature detects, categorizes, and redacts sensitive information in unstructured text documents and conversation transcripts, such as phone numbers, email addresses, forms of identification, and more.
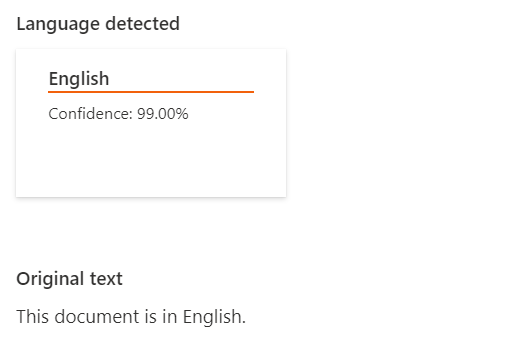
- Language Detection: This feature detects the language a document is written in and returns a language code for a wide range of languages, variants, dialects, and some regional/cultural languages.
- Sentiment Analysis and Opinion Mining: These features help you find out what people think of your brand or topic by mining text for clues about positive or negative sentiment and can associate them with specific aspects of the text.

- Summarization: This feature uses extractive text summarization to produce a summary of documents and conversation transcriptions. It extracts sentences that collectively represent the most important or relevant information within the original content.
- Key Phrase Extraction: This feature evaluates and returns the main concepts in unstructured text as a list.
- Entity Linking: This feature disambiguates the identity of entities found in unstructured text and returns links to Wikipedia.
- Custom NER: This feature allows you to create and train your own NER models with your own data and labels. You can use this feature to handle domain-specific terminology and scenarios that are not covered by the preconfigured NER models.
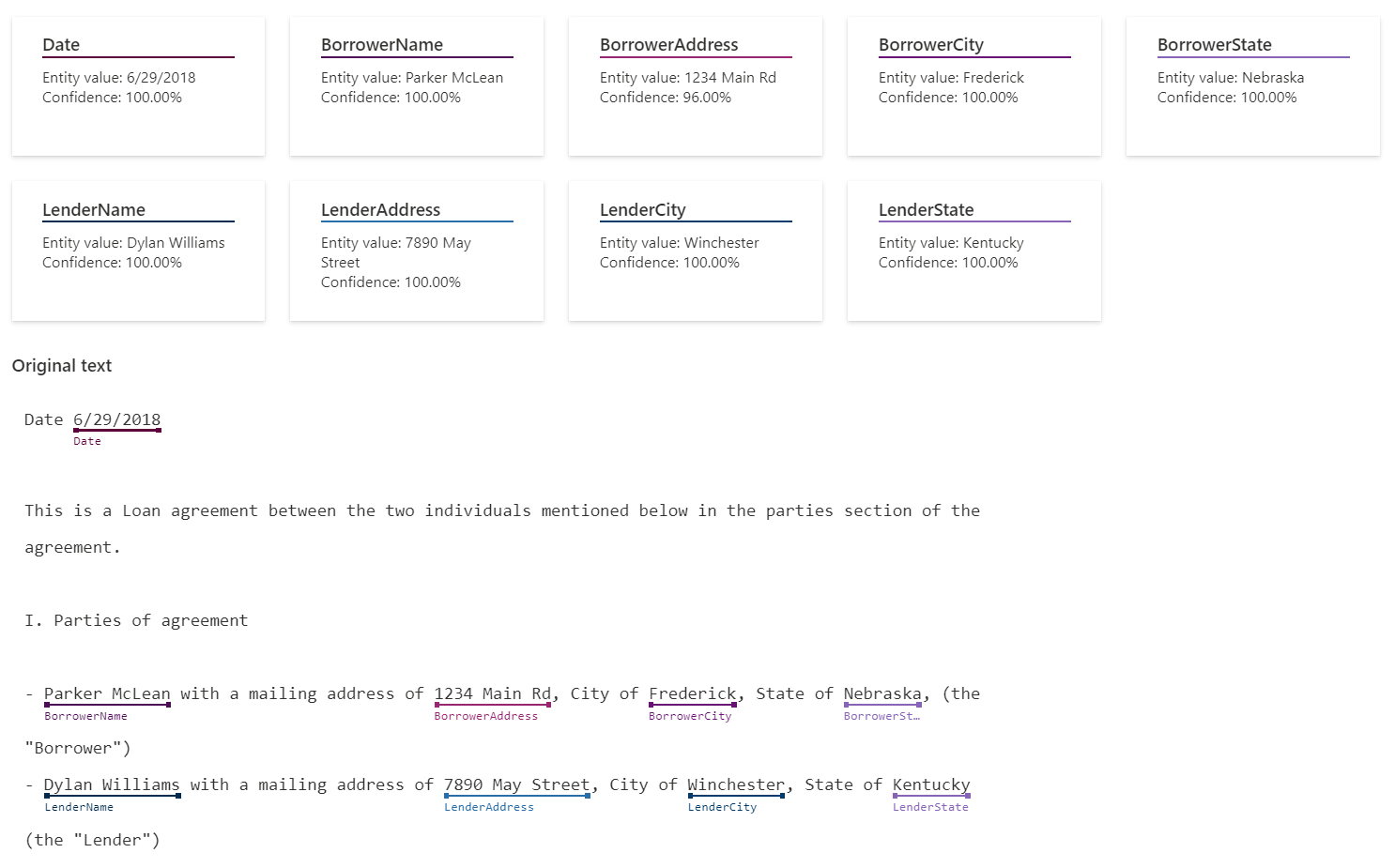
- Custom Classification: This feature allows you to create and train your text classification models with your data and labels. You can use this feature to categorize text into custom classes that are relevant to your business or application.
- Custom Single-Turn Question Answering: This feature allows you to create and train your own question-answering models with your own data. You can use this feature to provide answers to user questions based on a given context or document.
(all example images are sourced from the Microsoft page: What is Azure Cognitive Service for Language - Azure Cognitive Services | Microsoft Learn)
How can any of these features help you in your business
Democratization of AI has been a trend in the past few years & is now stronger than ever. Complex AI & ML models are now readily available and allow any business to easily integrate those models in applications, processes, etc. As the technology is now widely available, it is not technology, but your own creativity that limits the value you will be extracting from AI in the next few years. Here is a selection of use cases related to language and textual data, that could drive value for your organization.
Here are some examples of how you can use the Azure Language Cognitive Service features in your business:
- A news publisher could use NER to extract entities from articles and provide rich metadata for search and recommendation engines. They could also use sentiment analysis and opinion mining to understand how their readers react to different topics and stories.
- A healthcare provider could use PII and PHI detection to protect the privacy of their patients and comply with regulations. They could also use summarization to generate concise reports from medical records or transcripts.
- A customer service center could use custom NER to recognize product names, order numbers, or issue types from customer queries. They could also use custom single-turn question answering to provide automated responses based on a knowledge base or FAQ document.
- A law firm could use speech translation to communicate with clients or witnesses who speak different languages. They could also use custom NER to extract legal entities and terms from documents or transcripts.
- A marketing team could use text-to-speech to create voiceovers for their video campaigns and make summarized and integrated content that can be used across different channels (LinkedIn, Instagram, Mail campaign, …)
- A gaming company could use conversational language understanding to create immersive and interactive dialogues for their characters. They could also use entity linking to enrich their game world with relevant information from Wikipedia.
How can you get started and what do you need
To use the Azure Language Cognitive Service features, you will need an Azure account and a subscription to the Language service. Once you have these set up, you can access the features through the Language Studio web portal or the REST APIs and client libraries. Depending on the specifics of your use case, you may also need to use other Azure services such as Azure Storage for storing data or Azure Functions for processing data.
Language Studio enables you to use the service features without writing any code. You can create projects, upload data, train models, test models, deploy models, and monitor performance all from one place. You can also export your models as containers or endpoints for integration with your applications.
It’s important to carefully plan and design your use case to determine which Azure resources you will need to achieve your desired outcome.
What does it cost
As it is a cloud service, you pay as you go based on how much you use and which services you use. For the language models, the count is based on text records where one text record corresponds to a text of 1000 characters. If a text has more characters than 1000, the text records will always be rounded up.
If an input document contains 6500 characters, it would count as 7 text records. If you input two documents, one document with 6500 characters and another document with 400 characters, it would count as 8 text records (7 + 1).
Here is a non-exhaustive list of the pricing of Azure Language Cognitive Service (note that you get 5000 text records for free per month for almost all the services).
- For the standard text analytics features such as sentiment analysis, key phrase extraction, language detection, named entity recognition, and PII/PHI detection, you pay ~ € 0,9 per 1,000 text records for the first 500.000 text records, and then the price decreases as you process more text records.
- Summarizing documents costs ~ € 1,8 per 1000 text records. Both the input and the output are counted towards the number of text records.
- So if you summarize 40 documents (each containing 20 000 characters) to 40 summaries of 2000 characters, you will pay € 1,812 for this service
- For customized Named Entity Recognition and Text classification, you pay ~ € 4,5 per 1000 text records.
You can find more details about the pricing in the Microsoft Pricing calculator.
What's the difference with the OpenAI services
You might now wonder, what is the difference between the Azure Language Cognitive Service and the OpenAI GPT models? Because in essence, if we would input a text in the OpenAI service and we would ask to summarize this text or ask for the sentiment of the text, we would probably get what we're looking for.
The difference between Azure Language Cognitive Services and OpenAI GPT models is that they are different types of services that provide natural language processing (NLP) features. The first offers specific NLP services, whereas the latter offers a series of NLP models.
Azure Language Cognitive Services is a service from Microsoft that offers a variety of preconfigured and customizable NLP features as described above (named entity recognition, sentiment analysis, summarization, key phrase extraction, entity linking, ...). Each of these services is built for the specific task it's intended for. You can consider each service as a special force with very specific skills that they excel in whereas the OpenAI GPT models are much broader and can be used in a much broader, yet less specialized sense.
A last key differentiator is that Azure Language Cognitive Services also supports virtual networking and private endpoints for enhanced security when using NLP features within your business applications.
OpenAI GPT models are a series of large language models (LLMs) that can understand and generate natural language and code. They include GPT-4, GPT-3, Codex, and DALL-E models. OpenAI GPT models are trained using reinforcement learning from human feedback (RLHF), which means they learn from the preferences of human users in a constant feedback loop.
Both services can perform NLP tasks, but they have different strengths and limitations. In summary, Azure Language Cognitive Services is more suitable for specific and predefined NLP tasks that require customization and security. OpenAI GPT models are more suitable for general and creative NLP tasks that require flexibility and innovation.
Lastly, both services/models can be accessed in a very similar fashion: through REST APIs or client libraries. And of course, we can use the web-based Language Studio or the OpenAI Playground for a more graphical interface.
To conclude, like many things, both options would probably work for your business case, so it will boil down to your own assessment of cost, complexity ease of use, security but also personal preference.
How to get started
Do you think you have an interesting use case that could make use of the Azure Language Cognitive Service or the OpenAI LLM models? Do not hesitate to reach out and let’s discuss how it would practically work in your environment.
Stay tuned for the next post on the Azure Vision Cognitive Service!



