Introduction
Microsoft Fabric is the new Microsoft branded analytics platform that integrates data warehousing, data integration and orchestration, data engineering, data science, real-time analytics, and business intelligence into a single product. This new one-stop shop for analytics brings a set of innovative features and capabilities by providing a transformative tool for data professionals and business users. With Microsoft Fabric, you can leverage the power of data and AI to transform your organization and create new opportunities.
For more Microsoft Fabric topics 👉 Microsoft Fabric | element61
What is a Lakehouse, and why is it important
Data Lakehouse is the evolution of Data Warehouse, combining the data quality, consistency, and structure of the star schema with the flexibility and scalability of Spark compute on cost-efficient storage where data is stored in the open-source delta file format. Data Lakehouse brings the best of both worlds - datalake and data warehouse, datalake fulfils the demand of having raw data, running AI/ML use cases, and low-cost and high availability of the data, while data warehouse provides the data in a business readable format for company’s historical KPIs, self-service and in-depth analysis. With open-source delta file format, Data Lakehouse also eliminates the everyday challenges of a datalake such as data inconsistency, performance issues, etc.
Lakehouse in Modern Data Platform
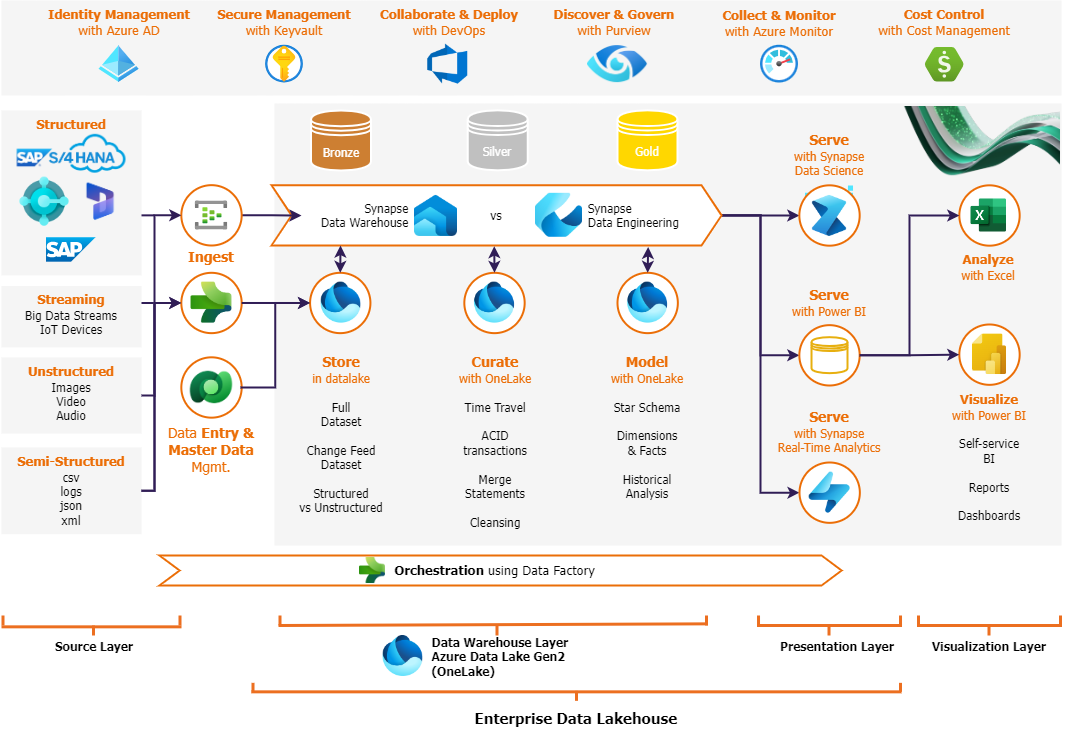
A Modern Data Platform should fulfill the needs of processing real-time streaming data originating from IOT or real-time events to be able to support AI/ML use cases and build real-time data products. At the same time, it should also support the needs of a traditional data warehouse, historical reporting, and batch processing. In the current Azure stack, in combination with Fabric components, a modern data platform architecture looks as follows where we have depicted the Lakehouse Medallion architecture.
In a Medallion architecture, data is stored first in a bronze layer in its most raw format as received from the source system; a data cleansing takes place in the silver layer and usually is stored in delta file format and finally in the gold layer data is aggregated and modeled for business purposes, data is modeled as facts or dimensions and again stored in delta file format.
How Fabric makes it easy to build the Lakehouse
With the right components of Fabric, it offers organizations the chance to start building the Lakehouses right from the word go. In one single SaaS (Software as a Service) platform it provides possibilities to do data ingestion, data processing, and data presentation with a variety of options like with coding in SQL or PySpark or even with no-coding with mapping dataflow gen2 or data factory pipeline activities. Finally, it also provides options to orchestrate end-to-end workflows from source till reporting. Once an organization has deployed a Fabric workload, it can start its Lakehouse journey. One must create a new Lakehouse from the Fabric workspace; the creation of a Lakehouse is available within the Data Engineering experience, as shown in the following depiction. Fabric workspace also allows us to create a lake-centric Data Warehouse from the Data Warehouse experience. The difference between two experiences and a decision guide will be covered in one of our upcoming insights.

Image 2 - Create a Lakehouse in the Fabric workspace
Three steps to build your Lakehouse in Fabric
Concerning the architecture diagram above, we have broken down the complex task of building a Data Lakehouse into three straightforward steps- a) Store data, b) Curate data and c) Model data. The following sections will provide a clear path towards establishing robust Lakehouse architecture within the Fabric ecosystem.
Store data in Lakehouse
Fabric has brought the best of the two worlds concerning copying data from the source– it can copy data with data factory pipelines copy-related activities, or it can get data from a variety of sources with dataflow gen2. To know more about these tools, please check out our other insight Creating a data lakehouse with Drag-and-Drop ETL in Microsoft Fabric. The data is then stored in the bronze layer. We can store the data either in its raw format a CSV, text, JSON or any other format or directly copy data in delta format. In Fabric, Microsoft has adapted the open-source delta format for storing data to leverage the benefits of delta. At the time of writing this insight, it is not possible to categorize bronze, silver and gold within the Tables of Lakehouse, so we can adapt the following approach.
One Fabric workspace allows for the creation of multiple Domains. Domains are the logical segregation of functionally different business units. The source data coming from various data sources is usually needed by cross domains unless the data source is very explicitly tied to the business domain. Hence, it would logically make sense to keep the bronze and silver data in a common domain while keeping the business-related gold data in their specific business domains. One workspace in Fabric allows for multiple Lakehouses, but they must be logically related to the domains, making it easier for consumption and data discovery. Below the pipeline is a simple illustration of a metadata-driven ingestion happening in Fabric.

Image 3 - Store data in bronze with copy pipelines
The data organization across multiple Lakehouses and domains can be depicted below; however, depending on the organization's size, number of users, complexity, maturity, and preference, it can be adjusted. You will get an idea about Lakehouse and the Fabric workspace management in another blog post of ours: Workspace Management in Microsoft Fabric.

Image 4 - Organize data across logical domains in Medallion Architecture
Curate data in Lakehouse
Data in the rawest format might not be helpful for data consumers. Hence, we would need several data curation and data cleansing before a data engineer or data scientist uses it. Dataflow Gen2 provides a no-code/low-code approach to clean the data tables that were loaded from external data sources in the previous step. A few examples of data curation are – formatting columns to correct dates or decimals, respecting uppercase or lowercase, removing duplicates, flattening nested data types, and several others.

Image 5 - Data curation with Dataflow Gen2
Microsoft Fabric also provides the option to work with spark notebooks where data cleansing can be performed by spark SQL or PySpark code as below.
Similar to data cleansing, data formatting can be achieved with Pyspark SQL or Python.

Image 6 - Data curation with Python
Model data in Lakehouse
After data cleansing, data needs to be modeled for further consumption by business users, especially when creating an analytical report for historical trend analysis. The model step enables the basis for setting up the star schema by creating dimensions and facts. While we still aim for a low-code/no-code approach for creating dimensions and facts, a more realistic approach would be to use spark notebooks (be it SQL-based or PySpark-based) or stored procedures with parameters to automate the creation of all dimensions and facts. The notebooks or stored procedures can be called from the data factory pipelines for as many dimensions or facts; at the same time, the freedom of running notebooks in several languages will enable extensive data transformations needed for the dimensions/facts.

Image 7 - Spark SQL Notebook to Model Dimensions and Facts
Orchestrate the three steps with Data Factory
When the above three steps - store data, curate data, and model data are achieved, the final task is to orchestrate the end-to-end Lakehouse for the required domains at the required frequency. Data Factory pipelines allow us to accomplish the same. Once again, we see Fabric is bringing together the capabilities of different worlds - a) Metadata-driven data pipelines to copy data, 2) Dataflow gen2 to curate data, and 3) the Power of Spark for modeling data. It is recommended that the orchestration is generic and parameterized as much as possible to simplify the process and increase reusability. Once the complete orchestration is done, Fabric data factory pipelines allow us to inform via Outlook emails or Teams notifications to inform businesses about the status of their Lakehouse.

Image 8 - Spark SQL Notebook to Model Dimensions and Facts
OneLake for data presentation
Fabric stores all data in “OneLake” - OneLake is the central denominator that connects the different fabric services: it serves as the shared storage location for ingestion, transformation, real-time insights, and Business Intelligence visualizations. Fabric developed the OneLake Explorer, enabling users to find their data in the OneLake Lakehouses. In the following depiction, you can see all the Lakehouse built in the Fabric workspace we used. We can browse the tables and files as well if there is a need for it.

Once there is data in the Fabric Lakehouse, there are several options for how consumers can consume it. We have depicted some of these options below – a) Connect with SQL server management studio or Azure data studio, b) Analyze in Excel, c) Directly create a report, d) Directly create a visual query, e) Create a new shortcut to explore data in other Lakehouses within Fabric and several others.
Maybe take this out in another insight, instead show the data factory orchestration.

Image 10 - Options for data presentation/data exploration
Room for improvements in Fabric Lakehouse
- Workload Isolation – Currently, Fabric runs all its workload under one Fabric capacity if you would like to know more about Fabric capacity – kindly check our other insight. In an enterprise-level environment, it would make more sense to isolate workloads for data engineers vs. data scientists vs. data analysts to gain more control over the data processing. element61 already submitted an idea to include this feature in Fabric, which can be found at Workload isolation in the Fabric cluster.
- Organization of Lakehouse(s) – With Fabric data domains, it is already possible to organize data as per business domains. Still, it would also make sense to have more flexibility within a Lakehouse to segregate the data as per the medallion architecture. In the end, we need clean structures for our data so they are easily accessible and discoverable with concrete governance put in place.
- CI/CD of Lakehouse Assets and Artifacts - While GIT integration is possible with the Fabric workspace, and we have deployment pipelines for deploying Power BI artifacts like dataflow, datasets we still need to extend our CI/CD process to be able to deploy artifacts across environments across different Fabric experiences. For example, we would want a similar way of deploying Data Factory artifacts in Fabric.
- A better way to load data from on-premises – Currently, in Fabric, we load data from on-premises using on-premises data gateways, which are not easy for maintenance reasons. Loading data through Synapse Spark notebooks is also possible, but it requires a complex network setup and is hard to maintain. We are sure there will be more ways in the future to load data from on-premises systems.
Conclusion
Despite a few missing features in its preview stage, Fabric as a SaaS platform unites the best of data lakes and data warehouses, a Fabric-based Lakehouse offers unparalleled advantages. Seamlessly integrate diverse data sources, leverage powerful analytics, and ensure real-time insights with enhanced performance and scalability. The power of building the Lakehouse from a low-code no-code approach to build with spark notebooks, the One-lake data hub, a variety of data transformation and data presentation techniques, and the direct lake mode to report real-time – it indeed stands for “One Unified Data Platform for all” and it is here to stay.


