Context
APIs are a powerful, well-established and efficient way to expose data and decouple the complexity of applications. At a certain point, your organization will need to share your data and the most pragmatic way is through an API (not an SFTP or excel). In this article, we will summarize how to build an API and expose your data to the outside world in Azure.
The architecture and role of each component
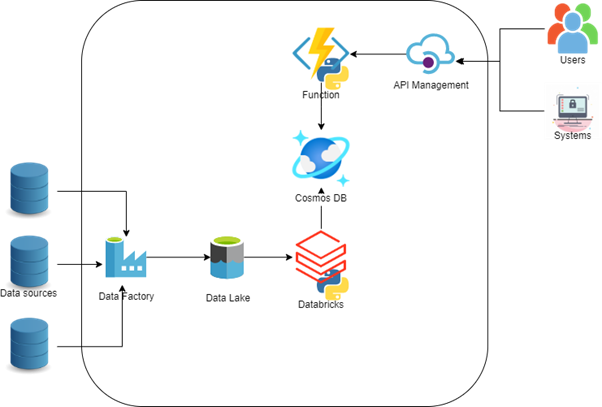
- Azure Data Factory ingests the data from multiple data sources into the Data Lake.
- Azure Data Lake (Azure Storage Gen 2) keeps the raw ingested data in a Delta-format available for broad analytics use.
- Azure Databricks processes the data from the Data Lake, transforms it & writes it to Cosmos DB.
- Azure Cosmos DB stores the data in a NoSQL format, provides a strong SQL engine and allows for horizontal scalability, replication, high availability, and minimal latency.
- Azure Function receives API calls and converts them to SQL queries, authorizes the calls and constraints them based on an access matrix. Can also be used to authenticate the users if API Management is not used.
- Azure API Management exposes one or more Azure Functions to the outside world, authenticates the users.
Lessons learned
Use the right package in Databricks to connect to Cosmos DB
Databricks doesn’t connect by default to Cosmos. To read & write to & from Cosmos, we recommend combining the latest Azure Cosmos Spark connector with the latest release of its connector and the latest available LTS (Long Term Support) Databricks runtime. Try out several connectors as the first one you install might not work with your Databricks runtime. At the time of the writing, we are using Databricks 10.4 LTS with the connector 3-2_2-12:4.10.0.
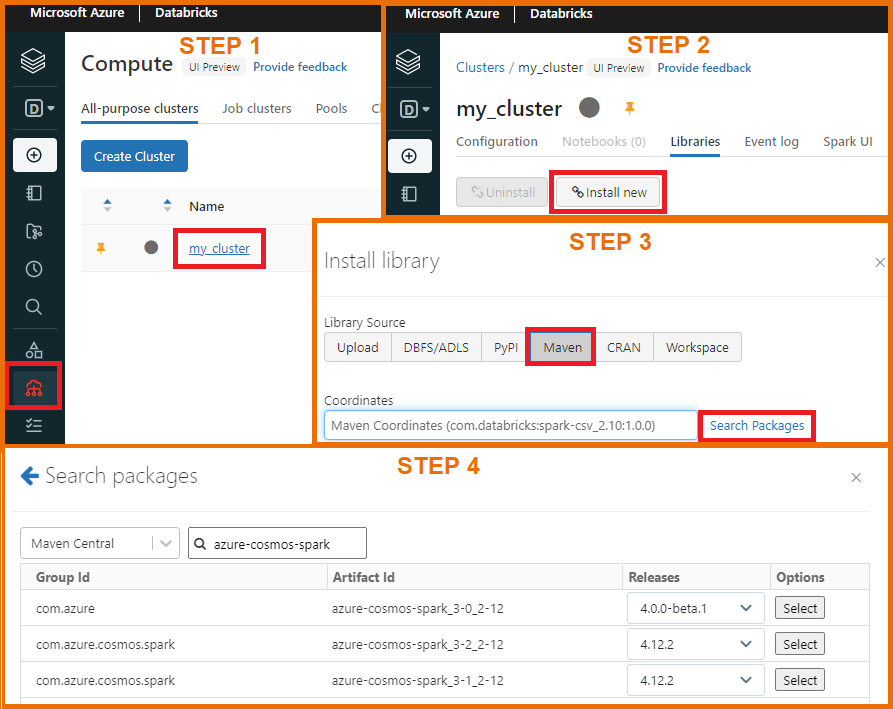
- Step 1: Open the Compute tab in Databricks as shown in the image below and click on your cluster.
- Step 2: In the Libraries tab of the cluster, click on Install new.
- Step 3: Select Maven and click on search packages.
- Step 4: Search for azure-cosmos-spark in Maven Central and you will find the connectors for several Spark versions.
Once the connector is installed, read and write data using the following commands:
from pyspark.sql import DataFrame
cfg = {
"spark.cosmos.accountEndpoint" : "https://your_cosmosdb_accountname.documents.azure.com:443/",
"spark.cosmos.accountKey" : "your_cosmosdb_primary_key",
"spark.cosmos.database" : "your_cosmosdb_database",
"spark.cosmos.container" : "your_cosmosdb_container"
}
# Good practice is to obtain your accountKey and accountEndpoint from the keyvault using dbutils.secrets.get
# Read data from the specified container
df : DataFrame = spark.read.format("cosmos.oltp").options(**cfg)\
.option("spark.cosmos.read.inferSchema.enabled", "true")\
.load()
# Write a pyspark DataFrame the specified container
df.write.format("cosmos.oltp").options(**cfg).mode("append").save()
Be smart in data modelling
Cosmos DB is a NoSQL database and data modelling is different to the traditional star schema for tabular data. You can & should use this NoSQL structure for your benefit by smartly modelling the data in line with how the API will request it.
Data modelling has huge consequences and the length, complexity, speed of execution of queries and indexing can grow rapidly. Use the following guidelines when deciding whether to embed or normalize your data.
Embed data models when:
- There are contained relationships between entities
- There are one-to-few relationships between entities
- There is embedded data that changes rarely
- There is embedded data with limited size and is not transactional
- There is embedded data that is queried frequently together
- The API users benefit from having the entity relationships
- The application logic that converts API calls to SQL queries can handle complex SQL queries
Use normalized data models when:
- The data changes often or is transactional
- Representing one-to-many relationships
- Representing many-to-many relationships
- Referenced data is of unbounded size
- Referenced data is not queried together
- The API users can process and infer the relationships in the data on their side
For a more detailed explanation and examples, we recommend reading these official Microsoft docs that can be found here: Data modeling in Azure Cosmos DB.
Parameterize Cosmos DB for throughput and costs optimization
Costs are easily run high as you try to get the API performant.
To balance throughput, performance & costs, we recommend:
- Choosing Serverless Cosmos DB tier when API calls are infrequent and simple (used for testing environment)
- Choosing Manual throughput when the API’s have a constant workload
- Choosing Manual throughput and scaling the container throughput programmatically using an Azure Function when there are heavy workloads at predictable/recurring times
- Choosing Autoscale throughput when the APIs have heavy and time-constrained workloads at unpredictable times
- Enforcing paging on the API results with reasonable limits, as expensive queries might be triggered by API calls and cause bottlenecks
- Indexing the data to speed up the most frequent API calls and reduce RUs used, especially useful for Serverless Cosmos DB, for time-constrained or complex queries
- Setting up alerts when the throughput exceeds a threshold over an unexpected period
- If queries are repetitive use the minimal manual throughput with a dedicated gateway to retrieve the data out of its cache and rarely make calls from it to the backend Cosmos DB. This applies only on a single region and cannot be provisioned on a virtual network
Think proactive about security & Access management
The response of the API should likely be different for every user. Not everybody with access to the API should be able to query the same data and/or query all API calls. This security & access management should be defined at API design.
To simplify security & access management Azure offers Azure API Management. With Azure API Management (APIM) in your architecture, you can authenticate the API users with Oauth 2.0 & APIM allows for other security and inbound processing rules, such as IP whitelisting, certificates etc. If you use APIM, we recommend authenticating your API users using API Management using the auth code grant flow.
If you don’t go for APIM & if you directly offer your Azure Function as an API endpoint, use MSAL for authenticating the users. This way of authenticating is recommended only if you don’t use API Management but needs to be configured & synced within your API as well.
Conclusions
Azure offers great PaaS components to support building an API on top of your Lakehouse. With Azure Functions & Cosmos it’s easy but the devil is in the detail. With the discussed tips you can save time & money. Here is a recap:
- Install and update your Databricks to Cosmos DB connector on every Databricks LTS runtime release
- Be smart in Data modelling as it has major consequences on the development time of the application logic, the way the data is consumed, the throughput of the API and its maintainability
- Be mindful of choosing the pricing tier of your Cosmos DB according to your needs, avoid writing or indexing redundant data and alert yourself on high provisioned throughputs
- Use Oauth 2.0 with tokens and access matrix that assigns these tokens permissions when authenticating your users and do so using API Management.
Want to know more?
By summarizing the above architecture, recommendations, and good practices, we encourage you to start building your APIs in Azure and start sharing your data with other applications outside your Azure ecosystem. To know more on building APIs in Azure, please contact us!



